We All Guessed Wrong
A discussion and proof that 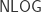

Neil Immerman and Robert Szelepcsenyi are two computer scientists who are famous for solving a long standing open problem. What is interesting is that they solved the problem at the same time, in 1987, and with essentially the same method. Independently. Theory is like that sometimes.
They solved the so called “LBA problem”. This problem was first raised in the 1960’s. When I was a graduate student we all knew about the problem. But no one thought about the question as far as I could tell. It stood unsolved for so long for two reasons, in my opinion. First, no one really worked on the problem. It appeared to be unapproachable. Second, we all guessed wrong. The conventional wisdom (CW) was that the problem went one way. That was obvious. But Immermann and Szelepcsenyi showed that it went the other way. Sound familiar? Could P=NP go the same way? Who knows?
There is one more comment I must add. Robert was a student when he solved the problem. The legend is that he was given a list of homework problems. Since he missed class he did not know that the last problem of his homework was the famous unsolved LBA question. He turned in a solution to the homework that solved all the problems. I cannot imagine what the instructor thought when he saw the solution. Note, it is rumored that this has happened before in mathematics. Some believe this is how Green’s Theorem was first solved. In 1854 Stoke’s included the “theorem” on an examination. Perhaps we should put P=NP on theory exams and hope

The LBA Problem
The LBA problem was first stated by S.Y. Kuroda in 1964. The problem arose in a natural way since in the 1960’s there was great interest in the power of various types of grammars. Grammars were used to describe languages. There was a hierarchy of more and more complex types of grammars. At the bottom were grammars for regular languages, next came context-free grammars. Then, came context-sensistive grammars which were very powerful. They could describe quite complex languages. A natural question that arose immediately is: if 

A language is context-sensitive precisely if it is accepted by a nondeterministic Turing machine whose work tape is exactly the same length as the input. Such a machine is called a Linear Bounded Acceptor or LBA. The LBA problem, then asked, whether or not such machines were closed under complements. That is whether or not if a language was accepted by an LBA, then so was it’s complement. Since LBA’s are nondeterministic, the CW was simple: there must be a context-sensitive language whose complement is not context-sensitive. Note, the intuition was reasonable: how could a non-deterministic Turing Machine with only linear space check that no computation accepted some input? The obvious methods of checking all seemed to require much more than linear space.
The Solution
George Polya suggests that when trying to prove something, often a good strategy is to try to prove more. This and other great suggestions are in his classic book: How to Solve It. The rationale behind his suggestion is simple: when you are proving “more” you often have a stronger inductive statement.
Neil and Robert did exactly this. They did not determine whether or not the start state can reach the final state. Instead they counted exactly how many states could be reached from the start. Counting how many states are reachable gives them a “Polya” type advantage that makes their whole method work.
The key to their solution is the following cool idea. Suppose that we have any set 

where each 
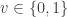

Further, the machine has some nondeterministic computation that outputs a sequence that ends in 
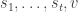

Let 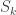

We now need to explain how they can create a weak generator for 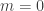


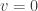
The key is this is a weak generator for
The last point is that we can construct the size of 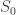
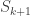
If the last is not 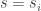
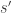
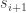
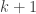
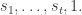
A Proof From the Sixties
With all due respect to Neil and Robert there is nothing about their clever solution that could not have been done 20 years ago. They solve the LBA problem directly, and they use no fancy methods or techniques that were developed during the last twenty years. It’s very clever, but there is nothing there that was unknown in the sixties. I often wonder whether there is some similar simple idea that would resolve P=NP? Is there some basic idea(s) that we are all missing? I hope that someone reading this will see something that we all have missed. That would be great.
Open Problems
An obvious question is: can any similar method be used to show that NP is closed under complement? One interesting note is that for their counting method to work they do not need to get the sets
Trackbacks
- Savitch’s Theorem « Gödel’s Lost Letter and P=NP
- An EXPSPACE Lower Bound « Gödel’s Lost Letter and P=NP
- It’s All Algorithms, Algorithms and Algorithms « Gödel’s Lost Letter and P=NP
- Surprises in Mathematics and Theory « Gödel’s Lost Letter and P=NP
- Guessing the Truth « Gödel’s Lost Letter and P=NP
- A Proof That P Is Not Equal To NP? « Gödel’s Lost Letter and P=NP
- Fatal Flaws in Deolalikar’s Proof? « Gödel’s Lost Letter and P=NP
- Busses Come In Threes, Why Do Proofs Come In Two’s? « Gödel’s Lost Letter and P=NP
- Polls And Predictions And P=NP « Gödel’s Lost Letter and P=NP
- Empirical Humility « Gödel’s Lost Letter and P=NP
- Giving Some Thanks Around the Globe « Gödel’s Lost Letter and P=NP
- Space Is Easier Than Time | Gödel's Lost Letter and P=NP
- Could We Have Felt Evidence For SDP ≠ P? | Gödel's Lost Letter and P=NP
- What is the proof that P=NP for LBA? - Quora
- Do results have a “teach-by-date?” | Gödel's Lost Letter and P=NP
- P=NP and Bitcoin | Gödel's Lost Letter and P=NP


“Note, it is rumored that this has happened before in mathematics.”…George Dantzig did something similar as a student. See http://en.wikipedia.org/wiki/George_Dantzig
The legend about Robert is not entirely true. Branislav Rovan was Robert’s master thesis advisor at Comenius University in Bratislava, Slovakia. While advising Robert, he showed him a table with known results for operations on languages. Complement for LBAs was empty but professor Rovan warned Robert that he should not spend time on it since it seemed to be a hard open problem. Robert didn’t listen and solved it in the end.
This story was told by professor Rovan (http://www.dcs.fmph.uniba.sk/~rovan/) during a lecture on LBAs while I was doing my master’s at Comenius University. You might try to ask him for further details.