A Most Perplexing Mystery
The discrete log and the factoring problem

Antoine Joux is a crypto expert at Versailles Saint-Quentin-en-Yvelines University. He is also one of the crypto experts at CryptoExperts, having joined this startup company last November. His work is featured in all three of the company’s current top news items, though the asymptotic breakthrough on the exponent of finding discrete logs in small-characteristic fields which we covered last month is not among them. In its place are concrete results on two fields of medium characteristic (between a million and a billion) whose elements have bit-size 1,175 and 1,425. The news release on this concludes (emphasis in original):
[We] recommend to all cryptographic users to stop using medium prime fields.
Today I want to talk about a mystery, which I find the most puzzling problem in all of complexity theory, but which Ken thinks is “only” a sign of youth of the field.
Read more…
A Trillion Dollar Math Trick
How linear algebra can make databases go really fast

Mike Stonebraker is one of the world’s leading expert on database technology. He started in academe at Berkeley, is now again in academe at MIT, and has launched a raft of successful companies. He is currently the co-founder and chief technology officer of at least three startups in the database area. One is called “Data Tamer” and is a joint venture with researchers from QCRI—Qatar Computing Research Institute—see this release.
Today I would like to talk about his presentation at the TTI Vanguard meeting on “Ginormous Systems” in DC. His talk was on “Seven Big Data Megatrends.”
By the way the word “Ginormous” is a real word–see here for the formal definition. I initially thought the Vanguard organizers had made up the word, but it is real. It should be obvious that Ginormous means large, actually really Large. This Vanguard meeting was dedicated to Ginormous systems of all kinds: from huge data centers, to city-wide systems, to supercomputers, and much more.
In Mike’s wonderful talk he made seven points about the past, present, and the future of database technology. He has a great track record, so likely he is mostly right on his guesses. One of his predictions was about a way of re-organizing databases that has several remarkable properties:
- It speeds up database operations 50x. That is to say, on typical queries—ones that companies actually do—it is fifty times faster than classical database implementations. As a theorist we like speedups, especially asymptotic ones. But 50x is pretty cool. That is enough to change a query from an hour to a minute.
- It is not a new idea. But the time is finally right, and Mike predicts that future databases will use this method.
- It is an idea that no one seems to know who invented it. I asked Mike, I asked other experts at the conference, and all shrugged and said effectively: “I have no idea.” Curious.
Let’s look quickly at the way databases work, and then consider the trick.
Some Background
Modern databases store records—lots of them, usually on disks. A record is a fixed-size vector of information. The vector is divided into fields, where a field stores a type of information. An example is:
![\displaystyle [name, address, home\text{-}number, cell\text{-}number, age, \dots ].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Bname%2C+address%2C+home%5Ctext%7B-%7Dnumber%2C+cell%5Ctext%7B-%7Dnumber%2C+age%2C+%5Cdots+%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
Thus the first field is the person’s name, the next the address, and so on.
In a sense the data is really stored in a table—or an array if you wish to be mathematical—call it 
The issue is how the array is stored on the disk. Each record is stored one after the other on the disk. The records are stored as

Here each 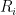

This is a reasonable method, it puts each record together, and allows fast access of all of the records. Thus, a query can scan over all the records by reading the disk one track at a time. This is not a bad way to use a disk-like device.
Mike points out that all the classic database systems—well at least most—store records in this manner. Their code, which also is huge (if not ginormous) is tuned to handle data that is stored in this manner. Let’s call it the “record ordered method” (ROM). As a mathematical idea it is just storing the array in row-major order. Not only is this a perfectly fine way to organize the data, and to store the array, it respects principles that go back to COBOL in the 1950’s: Each data object should be conceptually and physically together.
But there is a better way.
The Trick
The trick to the 50x speedup is based on the deep, advanced, complex operation that we in math call the transpose of a matrix. Just kidding. It is based on the simple idea that instead of storing the matrix 

Let’s call this the column ordered method: COM. Now the data on the disk contains

Here each 

So why is this method so much faster than the ROM? The answer is how the data is accessed by the queries. The data is read much more than it is written, so the key is to speed up the ability to read the data. But the critical insight is this:
A query is likely to use only a few columns.
For example, suppose the query is:
Select all the records with age in the range [21,31] and cell phones with area code 404.
Then the query needs only to look at two columns. All the other fields are completely un-needed.
Now suppose the records have a hundred fields. Since the query only looks at two fields there is a huge speedup. Then the speedup is 

Clearly if a record has even one large field that is not used in the query, the speedup could be very large.
How did people not realize this simple idea: replace the table
Whose Trick?
As I stated earlier no one seems to be able to say who exactly discovered the COM. Maybe as a default we could call it the Gauss Database Method, since most things are named for him. I did track down a system called TAXIR that was essentially a COM storage system with focus on information-retrieval in biology in 1969. The paper describing it is by George Estabrook and Robert Brill. Maybe they invented it. Perhaps their focus on biology made it hard for those in databases to notice their work? Especially years ago before powerful on-line search engines. Perhaps.
Ken adds that in a textbook used years ago for Buffalo’s course on programming-language concepts, the COM idea was called “parallel arrays” and was frowned upon. The main reason given was that this structure was hard to maintain, as a single off-by-one indexing error in one array could damage the entire set of records. However, a high-level system can maintain the data in-sync, while modern machine architectures increase the reward for keeping just the data you need in caches.
Open Problems
Okay, maybe the trick is not worth a trillion dollars. But the total amount invested yearly in data systems suggests that the column idea could over the next few years be worth quite a few dollars.
A simple thought: Is the column method the best way to store records? Can we in theory prove it is best in some sense, or is there an even better method? So forget the million-dollar Clay prizes and go after the real money.
Happy Birthday, Kurt Gödel
Wang on Gödel, and Gödel on Wang

|
|
source, with more Wang quotes |
Hao Wang was a logician who made many important contributions to
mathematics and especially logic. His creation of the now famous tiling problem was of great importance. He did seminal work on mechanical mathematics, getting in 1983 the first Milestone Prize for Automated Theorem-Proving. Perhaps one of his best “results” was being the PhD advisor to Stephen Cook, Shimon Even, Stål Aanderaa, Joyce Friedman, and a recent invention-prize co-winner whom we mention below.
Today Ken and I wish to point out that it is Kurt Gödel’s birthday. Read more…
Sex, Lies, And Quantum Computers
Okay, no sex, but a discussion about quantum computers.

Steven Soderbergh directed the famous movie: Sex, Lies, and Videotape. This 1989 movie won the Palme d’Or at the 1989 Cannes Film Festival, and is now in the United States Library of Congress’ National Film Registry for being “culturally, historically, or aesthetically significant.”
Today I want to explore claims about quantum computation.
Read more…
Can We Prove Better Independence Theorems?
An approach to independence with more complexity dependence

Florian Pelupessy recently defended his PhD thesis at the University of Ghent in Belgium. In joint work with Harvey Friedman, he found new short proofs for two independence results from Peano Arithmetic. One result is the famous “natural” Ramsey-theoretic independence result proved by Jeff Paris and Leo Harrington in 1977, while the other is a different Ramsey-type result obtained in 2010 by Friedman. Pelupessy also maintains a page with links on “phase transitions” in proof theory—meaning cases where a slight change in values of parameters makes a statement go from being provable to independent.
Today I want to talk about whether we can prove that some of our open problems are independent of Peano Arithmetic or other theories. Read more…
Subset Powers of Graphs
A possible way to extend the idea of matchings?

|
|
source—interesting genealogy |
Johann Pfaff was a German mathematician of the late 18th and early 19th century. He is best known for the fact that the determinant of a skew-symmetric matrix 




Today Ken and I want to talk about a kind of graph powering that may be new, and that may relate in some cases to Pfaffians. Read more…
Measures Are Better
The Littlewood conjecture—another drive you crazy conjecture

John Littlewood is the latter half of famous duo of Hardy-Littlewood. I have discussed him before here and only wish to point out that he was, on his own, one of the great analyst of the last century.
Today I will discuss the Littlewood Conjecture, which has been open now for over eighty years.
Zeno Proof Paradox
Another discussion of paradoxes

|
|
src |
Zeno of Elea was a Greek philosopher who lived almost 2400 years ago. He is famous for the creation of paradoxes at the juncture of mathematics and the real world.
Today Ken and I want to talk about a type of Zeno paradox. Read more…
Interstellar Quantum Computation
Proof from the Chelyabinsk bolide fragment

|
|
source |
Viktor Grokhovsky is a member of the Russian Academy of Science’s Committee on Meteorites. He is on the faculty of Ural Federal University, and specializes in metallurgy. He has been coordinating the recovery of fragments of the bolide that blazed and exploded over the skies of Chelyabinsk in southern Russia on the morning of February 15th. The largest known piece fell into icy Chebarkul Lake about forty miles southwest of the city.
Today we are delighted to convey findings from metallic crystallographic analysis of the interior of the fragment, and discuss their significance for the reality and prospects of scalable quantum computation.
Read more…
Happy 100th Birthday, Paul Erdős
Fixing our own Erdős discrepancy

|
|
By permission of Fan Chung Graham, artist. |
Paul Erdős—Erdős Pál in Hungarian—would have been 100 this past Tuesday. He was a force of nature, a world stimulant. He popularized his colleague Alfred Rényi’s dictum that “a mathematician is a machine for turning coffee into theorems,” while supplying much of the perpetual motion for the world’s theorem-proving machines himself. His Wikipedia page lists his affiliations after leaving Notre Dame in 1952 as “itinerant,” though he was a regular visitor to several institutions around the world. Although known for long travels, he also experienced the shortest possible transit, from Memphis State University to the University of Memphis in 1994. His frequent collaborator Joel Spencer cited words delivered by Ernst Straus to honor Erdős’ 70th birthday, in 1983:
Just as the “special” problems that [Leonhard] Euler solved pointed the way to analytic and algebraic number theory, topology, combinatorics, function spaces, etc., so the methods and results of Erdős’ work already let us see the outline of great new disciplines, such as combinatorial and probabilistic number theory, combinatorial geometry, probabilistic and transfinite combinatorics and graph theory, as well as many more yet to arise from his ideas.
Today Dick and I would like to join others observing this important anniversary.

