A Negative Comment on Negations
Always turn a negative situation into a positive situation—Michael Jordan (MJ)

|
| src |
Michael I. Jordan of the University of California, Berkeley, is a pioneer of AI that few outside of his field recognize. “He’s known as the Michael Jordan of machine learning,” quips Oren Etzioni, director of the Seattle-based Allen Institute.
Today, Ken and I discuss some linkage between machine learning and computational complexity theory.
The quip by Etzioni runs longer—see this. The Allen Institute’s Semantic Scholar project aims to achieve content-based associative search for academic publications, so one can search for X that are close to a topic Y you have defined. They created an “influence graph” for millions of academic publications that goes well beyond citation counts. The graph’s most influential computer science paper was one by Jordan.
Neither Jordan has ever worked in complexity theory. Somehow, I thought the above is relevant to complexity theory. It got me thinking about MIJ and his connection to machine learning (ML). This is connected to complexity theory again, and so 
My thoughts converged on how the notion of monotone plays in both fields. Influence strikes us as naturally monotone—“negative influence” is still influence—and building the graph is a kind of positively weighted transitive closure. Many ML algorithms work by monotonically increasing an objective function, such as expectation-maximization as expounded by MIJ. Non-monotone components such as negative (inhibiting) neural links and line–search add-ons to gradient descent are employed, but when and to what extent are they critical? We think negation is critical in complexity theory, but maybe not so much. Here are my thoughts.
Upper Bounds and Lower Bounds

Complexity theory is all about how hard is it to solve some problem. How hard is it to decide if a number is a prime? How hard is it to find a factor of a composite number? How hard is to color a graph with three colors? And so on.
There are two issues:
Upper Bounds Find an algorithm for the problem that is more efficient in some manner. Often in number of steps, but can be in other measures of complexity like memory used or amount of randomness and so on.
Lower Bounds Show that no algorithm for the problem is more efficient in some manner. For example, show that no algorithm can solve the problem is fewer than a certain number of steps.
The first is an 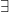
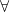
There is something about
The lower bound requires you to show that there is no algorithm that operates more efficiently that a certain bound. You must show that being too fast, for example, makes you wrong.
Negations
One approach to lower bounds is via Boolean complexity. The idea is that any computation can be done with 


Suppose that you wish to show that something cannot be computed efficiently. An obvious first step is to explain what operations are needed to compute it at all. Once you fix on operations that are enough, you can then focus on the question of whether the given operations can efficiently compute it.
Suppose you wish to show that it will take a long time to get from A to another location B. How can you prove this? You might measure how long the distance is between A and B. Then if you know that you must drive a car from A to B, a lower bound is simple: How fast can the car go at maximum and argue that the time is therefore at least

Here M is the maximum speed the car goes.
Suppose that Distance is 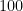
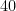

Of course it could be higher if sometimes you go slower—perhaps you have to stop now and then for traffic lights.
Monotone Circuits
There are many theorems like this:
Theorem 1 Any monotone circuit that computes
correctly has size at least exponential in
.
These theorems are often hard to prove and require clever methods, but there are now tons of them. The field of complexity continues to extend and refine these theorems.
This feeds in to the approach of showing 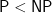

But there is a big issue: it takes only order 
This failure led many to think that negations are somehow the “final frontier.” But we do not agree with this either. We feel that negations are not the critical issue.
The Slice Issue—Again
The key is the concept of slice. A slice of 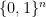


There are many theorems like this:
Theorem 2 Any monotone circuit that computes
For a simple insight, suppose we want to say that a given bit 





For an example of how slices show that negations cannot be the issue, consider factoring of 


We still have not said anything new. This insight says that strong lower bounds on monotone complexity for slice functions will give lower bounds for general circuits. But we still do not know how to get such bounds. We have shifted around the side of the mountain, but the resulting “Slice Gap” seems to block ascent as before.
Climbing Mount ML
This is what has me thinking about whether machine learning can supply new insight.
Here is a simple old story of what I mean. One of the limits on the simple neural model of perceptrons that was shown a half-century ago by Marvin Minsky and Seymour Papert is that they cannot compute the binary XOR function. This led people to expect that small assemblages of perceptrons would be similarly powerless. But it only takes three layers of perceptrons to compute XOR. The point is, a small control structure over monotone can replace the free use of negation.
To go deeper—into deep learning for instance—we’ve peeked at the book Understanding Machine Learning: From Theory to Algorithms by Shai Shalev-Shwartz and Shai Ben-David. The latter we know for some work on Boolean circuits and P=NP. The nub is more easily approached via a 2014 talk by the former, titled “On the Computational Complexity of Deep Learning,” and his 2016 followup. One point is that “theoretically weak” structures perform well when requirements of worst-case correctness and realizability are lifted—and the details make us wonder about possible parallels to the case of slices. The point also prompts us to ask:
What control structures, or intermediate operations short of full negation, create practically powerful algorithms that are still theoretically nearly as weak as monotone? Can researching them help us close the gap on lower bounds?
To go wider, it seems that both we humans and ML algorithms perform well at many tasks using largely monotone components. Can they help give an account relevant to complexity of what power necessarily comes from non-monotone components? We note caveats expressed by MIJ in a much-noted 2014 interview for IEEE Spectrum about generalizing from brain function to ML practice, but our intent is to look for particulars.
Open Problems
Can machine learning help us understand the power of monotone functions?


What’s all this stuff about invalid security tokens?
I’ll try again …
Re: Negative Thinking
Cf: Paradisaical Logic and the After Math
Negative operations (NOs), if not more important than positive operations (POs), are at least more powerful or generative, because the right NOs can generate all POs, but the reverse is not so.
Re: But it only takes three layers of perceptrons to compute XOR.
I don’t think a status of 3rd class citizen is all that much consolation to XOR and her dual EQ, who deserve to be 1st class citizens in the first place.
Minsky and Papert’s Perceptrons was the work that nudged me over the limen from gestalt psychology, psychophysics, relational biology, etc. and made me believe AI could fly. I later found out a lot of people thought it had thrown cold water on the subject but that was not my sense of it.
The real reason Rosenblatt’s perceptrons short-shrift XOR and EQ among the 16 boolean functions on two variables is the adoption of a particular role for neurons in the activity of the brain and a particular model of how neurons serve computation, namely, as threshold activation devices. It is as if we tried to do mathematics using only the inequality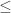 instead of using equations. Sure, you can circumlocute it, but why? Of course,
instead of using equations. Sure, you can circumlocute it, but why? Of course, 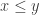 for boolean variables
for boolean variables 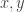 is equivalent to
is equivalent to  so this fits right in with the weakness of implicational inference compared to equational inference rules.
so this fits right in with the weakness of implicational inference compared to equational inference rules.
But there are other models for the role neurons play in the activity of the brain and the work they do in computation.