The 2020 Y Prize
Can one maintain privacy while publicly congratulating?

|
| Cropped from X Facemask src |
X, who shall go nameless here, recently won a prize for research.
Today we congratulate X and wish to talk a bit about their work while safeguarding X’s identity.
X also won another prize Z—but we will not mention which one. In both cases the honor is about the creation of a new field rather than the solution of a long-standing open problem. Her—OK, X is a she—brilliant work has allowed many others to write papers in these areas. And it has led to countless conferences, meetings, and talks.
Oops, we used the word “brilliant.” That has already leaked her identity, given where you are reading this. Just type it into our search box.
We assume you get the point. One can leak information about people without mentioning them directly.
The Real Start of the Post

|
| Her work in Algorithmic Fairness too |
Cynthia Dwork is the winner of the 2020 Donald E. Knuth Prize. The prize is awarded jointly by ACM SIGACT and the IEEE Computer Society Technical Committee. The ceremony will include a lecture by Cynthia at FOCS 2020, which is still projected to meet in-person at Duke next November 16–19.
Today we congratulate Cynthia and talk a little about her work.
I, Dick, have known her for many years. I am excited to see that she has won the Knuth prize.
She has always been a top researcher and a terrific speaker. I fondly recall some of her earlier talks at Princeton and elsewhere. There is something about her ability to explain complex ideas in a lucid manner. I have often thought that this ability must be one of the reasons she has been so successful in her research.
We will talk a little about differential privacy (DP) and then her other joint work which led to another prize. We should be quick to mention that others have been instrumental in both developments.
Quantifying an Idea
DP might have been appreciated long before there were large databases and computer systems. The genius is not just the simplicity of the idea but the development of mathematical tools to govern its application.
For a simple example, suppose a professor has a general policy of posting exam average scores in her class of 100. Suppose she posts that the average is 73.3 after 98 students have taken the exam but two need to make it up a week later. Then suppose she re-posts the average after they take it and it is 72.5. The difference may not seem like much. But the class learns two things:
- Both students had their makeup scores included in the average. (If the 73.3 is exact then it is not even possible to get a rounded 72.5 with just one score of zero, pending the other.)
- The two students collectively bombed the exam. (Just possibly one got a zero while the other did OK, but even then the other’s score was below average.)
Your first thought might be that the fault is in the excessive precision in the grade reporting. If she had rounded to the nearest integer then both averages would have been reported as “73” and there would be no problem. But rounding is accidental. The new average could have been 72.49, which would be rounded down to “72,” when the set of possible interpretations is worse than before.
In wide-scale situations where queries for multiple averages at different times are allowed, effects of rounding may cancel so that a large statistical analysis can subtract them out. Thus passively reducing precision is not enough. The key is to affect the precision actively by adding a random 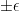

Adding
, better than rounding, makes inference much harder.
In the exam-score example, randomly adding or subtracting a number between 0 and 2 changes the calculus so that seeing “73.3” and then “72.5” does not allow a high-confidence inference about the makeup students’ scores. One could reason that the first number could easily have been 72.3 and the second 73.5, in line with interpretations where the makeup students upped the average. Actually, a jump from 72.3 to 73.5 in the true averages is impossible from just two new scores, so the class could deduce that the reported averages are fudged. But that is OK. Two basic purposes of reporting the averages are met despite the fudging:
- to show the exam was consistent with past years—especially good to know this year;
- to give you some idea (knowing your own score exactly) where you stand relative to the class.
In related situations, one could argue that a mean of 

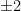
We do not intend our example to be definitive, only that it conveys relevant issues. The example is enough to convey that DP leads into deep matters in statistics and what can be inferred by statistical methods. The latter melds the complexity-theoretic notion of knowledge gain from interactive protocols with statistical (machine) learning. And as with quantum computing, theorems and methods from the subfield have come back to inform fundamental questions about complexity (of course, this is true of crypto in general).
Privacy and Online Chess
I, Ken, am the lead on this post, and have had data-privacy affect me personally. The pandemic has forced the cancellation of all over-the-board (OTB) tournaments, some as far ahead as August. Chess has all moved online, as heralded by two recent articles in the New York Times and one in the Wall Street Journal proclaiming, “Sports: Chess Is the New King of the Pandemic.”
As these articles also note, cheating has long been a major concern for online chess. I have been a recourse for second-opinions in online cheating cases but have not tried to be primary in this domain. A great conversation in November 2006 with Daniel Sleator (who—besides being famous for splay trees and amortized analysis—co-founded the Internet Chess Club) told me how online cheating detection avails much information about the manner of play that is not applicable or reliably available in OTB chess. Also for academic reasons, I chose a minimal approach of using no information besides the moves of the games and the Elo ratings of the players. An unexpected advantage of that choice is exemplified by an e-mail I received—fifteen minutes before a conference call on Wednesday with representatives of the International Chess Federation (FIDE) and other online platforms—from a different chess organizer requesting a statement that:
…you will only use the data of the games, and not any personal data that might be obtained from the [tournaments] for your research, such as player name etc. … in writing as a standard precaution … to make sure that there isn’t third party usage of the data or usage outside of its intent.
Some recent legal decisions have confirmed that the moves of the games are public data and cannot be copyrighted. The e-mail did not mention the players’ ratings. As used by FIDE and the US and most online platforms (and much more widely), those are 4-digit numbers, and they are public. Knowing all four digits might be enough to pinpoint the identity of a player.
Thus I suggested rounding the rating to the nearest 10 or even 20. This makes little difference to my statistical cheating tests, which already give 25 Elo points benefit-of-doubt for uncertainty about the rating. Tournament officials I’ve served have done this in a couple of individual cases but now the need is en masse.
The question based on the previous section above is whether I should instead (or also) suggest that they implement full DP by adding 

The Other Prize
The Knuth Prize is not Cynthia’s only win for 2020. In December she was awarded the 2020 IEEE Richard W. Hamming Medal. A video gives a one-minute summary of differential privacy and her work on non-malleable cryptosystems via lattice bases. The latter stems from her 2000 paper with Danny Dolev and Moni Naor (DDN).
We have not covered this crypto topic before. It involves chosen-ciphertext attacks where Eve, the evesdropper, first gets hold of a transmitted ciphertext 
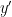




One would think that
Note: both fax machines and the paper date to the previous millennium. But the paper next gives an example that is staying with us in this millennium, where 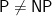
A Video
En-passant of this, we want to note a great video that was made for next month’s Women in Theory workshop. It has an all-female cast and lyrics by Avi Wigderson parodying the song “I Will Survive.” Cynthia is not in the video, but she likewise has been a great spokesperson for the experiences of women in our professional life.
Open Problems
Our congratulations again to Cynthia—by name—on the Knuth and Hamming prizes.


This support of Dr. Dwork is much better than what is given here https://rjlipton.wordpress.com/2020/04/10/nina-balcan-wins/. I still wonder if Dr. Balcan really did accomplish substantial. I am still clueless what is novel in the other work?
Censored to prevent necessary attention?