A visual proof with no abstract-algebra overhead
Dominique Perrin and Jean-Éric Pin are French mathematicians who have done significant work in automata theory. Their 1986 paper “First-Order Logic and Star-Free Sets” gave a new proof that first-order logic plus the 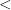 relation characterizes star-free regular sets.
relation characterizes star-free regular sets.
Today we present their proof in a new visual way, using “stacked words” rather than their “marked words.” We also sidestep algebra by appealing to the familiar theorem that every regular language has a unique minimal deterministic finite automaton (DFA).
The first post in this series defined the classes  for star-free regular and
for star-free regular and ![{\mathsf{FO}[<]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BFO%7D%5B%3C%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) for first-order logic where variables
for first-order logic where variables  range over the indices
range over the indices  of a string
of a string  of length
of length  . For any character
. For any character  in the alphabet
in the alphabet  there is the predicate
there is the predicate  saying that the character in position
saying that the character in position  of equals . The first part proved that for any language
of equals . The first part proved that for any language  there is a sentence
there is a sentence  using only predicates
using only predicates  and the relation
and the relation  besides the usual quantifiers and Boolean operations of first-order logic. such that defined
besides the usual quantifiers and Boolean operations of first-order logic. such that defined  . That is, it proved
. That is, it proved ![{\mathsf{SF}\subseteq\mathsf{FO}[<]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BSF%7D%5Csubseteq%5Cmathsf%7BFO%7D%5B%3C%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
A key trick was to focus not on but on a formula  expressing that the part of from position
expressing that the part of from position  (inclusive) to
(inclusive) to  (exclusive) belongs to . To prove the converse direction,
(exclusive) belongs to . To prove the converse direction, ![{\mathsf{FO}[<]\subseteq\mathsf{SF}}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BFO%7D%5B%3C%5D%5Csubseteq%5Cmathsf%7BSF%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , we focus not on middles of strings but on prefixes and suffixes. The previous post proved two lemmas showing that if
, we focus not on middles of strings but on prefixes and suffixes. The previous post proved two lemmas showing that if  is star-free then for any string
is star-free then for any string  , so are its prefix and suffix languages:
, so are its prefix and suffix languages:

We will piece together star-free expressions for a multitude of  and
and  sets that come from analyzing minimum DFAs
sets that come from analyzing minimum DFAs  at each induction step, until we have built a big star-free expression
at each induction step, until we have built a big star-free expression  for . This sounds complex—and is complex—but all the steps are elementary. At the end we’ll try to see how big gets. Again the rest of this post up to end notes is written by Daniel Winton.
for . This sounds complex—and is complex—but all the steps are elementary. At the end we’ll try to see how big gets. Again the rest of this post up to end notes is written by Daniel Winton.
Stacked Words and FO Formulas
We implement the “marked words” idea of Perrin and Pin by using extra dimensions rather than marks. Consider any formula  in FO[] where
in FO[] where  are the free variables. Our "stacked words" have extra rows underneath the top level holding the string . Each row has the same length as and contains a single
are the free variables. Our "stacked words" have extra rows underneath the top level holding the string . Each row has the same length as and contains a single  and
and 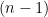
 s. The column
s. The column  in which the lies gives the value of the variable
in which the lies gives the value of the variable  . Thus the alphabet of our stacked words is
. Thus the alphabet of our stacked words is  . Here is an example:
. Here is an example:

Each column is really a single character  , but we picture its entries as characters in or
, but we picture its entries as characters in or  . For any row , define
. For any row , define  to be the disjunction of
to be the disjunction of  over all
over all  that have a in entry , and define
that have a in entry , and define  similarly. Then the following sentence expresses the “format condition” that row has exactly one :
similarly. Then the following sentence expresses the “format condition” that row has exactly one :
![\displaystyle (\exists k)[Y_{i,1}(k) \land (\forall \ell) [\ell \neq k \rightarrow Y_{i,0}(k)]].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%28%5Cexists+k%29%5BY_%7Bi%2C1%7D%28k%29+%5Cland+%28%5Cforall+%5Cell%29+%5B%5Cell+%5Cneq+k+%5Crightarrow+Y_%7Bi%2C0%7D%28k%29%5D%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
This readily transforms into a star-free expression for the language of stacked words with exactly one in row :

Here  is the union of all stacked characters that have a in entry , and
is the union of all stacked characters that have a in entry , and  is similarly defined. This is where the examples in the previous post about finite unions inside stars come in handy. The upshot is that
is similarly defined. This is where the examples in the previous post about finite unions inside stars come in handy. The upshot is that

is a expression that enforces the “format condition” over all rows. We will use this at the crux of the proof; whether  is really needed is a question at the end. If we take the format for granted, then the main advantage of our stacked words will be visualizing how to decompose automata according to when the in a critical row is read.
is really needed is a question at the end. If we take the format for granted, then the main advantage of our stacked words will be visualizing how to decompose automata according to when the in a critical row is read.
From FO To SF
The proof manipulates formulas  having the free variables shown. The corresponding language
having the free variables shown. The corresponding language  is the set of stacked words that make
is the set of stacked words that make  true, where for each
true, where for each 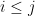 ,
, 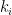 is the position of the lone in row , which gives the value of .
is the position of the lone in row , which gives the value of .
Theorem 1 For all formulas  over
over ![{\mathsf{FO}[<]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BFO%7D%5B%3C%5D%7D&bg=e8e8e8&fg=000000&s=0&c=20201002) ,
,  .
.
Without loss of generality we may suppose  is in prenex form, meaning that it has all quantifiers out front. If there are
is in prenex form, meaning that it has all quantifiers out front. If there are  variables of which are free, this means
variables of which are free, this means

where each 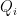 is
is 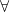 or
or 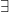 and
and  has no quantifiers. If we picture the variables as once having had quantifiers
has no quantifiers. If we picture the variables as once having had quantifiers  , then the proof—after dealing with —restores them one at a time, beginning with
, then the proof—after dealing with —restores them one at a time, beginning with  . That is the induction. We prove the base case here and the induction case in the coming sections.
. That is the induction. We prove the base case here and the induction case in the coming sections.
Proof: Quantifier free formulas in are Boolean combinations of the atomic predicates  and
and  . Here is only for the characters
. Here is only for the characters  , not the stacked characters . But inside (when we have
, not the stacked characters . But inside (when we have  ) we have to deal with the whole stack to represent . Putting
) we have to deal with the whole stack to represent . Putting  , the expression can be viewed schematically as:
, the expression can be viewed schematically as:

As illustrated above, using the initial lemma in the part-1 post, this is equivalent to a star-free regular expression. The other atomic predicate, , is true when we have a stacked word  of the form:
of the form:

It is not important to have  ; these are just the labels of the variables. Their values
; these are just the labels of the variables. Their values 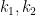 must obey
must obey  , meaning that the in row
, meaning that the in row  comes in an earlier column than the in row . The characters of in the top row are immaterial. We can capture this condition over all strings over
comes in an earlier column than the in row . The characters of in the top row are immaterial. We can capture this condition over all strings over  by the expression:
by the expression:

Again by the lemma in Part 1, this yields a star-free expression. To complete the basis, we note that if 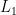 and
and 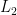 have star-free expressions
have star-free expressions  and
and  corresponding to
corresponding to ![{\phi_1, \phi_2\in \mathsf{FO}[<]}](https://s0.wp.com/latex.php?latex=%7B%5Cphi_1%2C+%5Cphi_2%5Cin+%5Cmathsf%7BFO%7D%5B%3C%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , then
, then  is represented by
is represented by  and
and  by
by  , both of which are clearly star-free.
, both of which are clearly star-free.
Strategy For the Induction Case
Assume that all formulas in with  quantifiers have star-free translations. We will show that any formula in with
quantifiers have star-free translations. We will show that any formula in with  quantifiers also has a star-free translation. Let
quantifiers also has a star-free translation. Let  where is a formula in that has
where is a formula in that has  total variables, free variables and
total variables, free variables and  quantifiers. We are allowed to assume the first quantifier in
quantifiers. We are allowed to assume the first quantifier in  is existential as
is existential as  and we observed above that the star-free expressible formulas in are closed under negation.
and we observed above that the star-free expressible formulas in are closed under negation.
The language of is given by:
 we can add a
we can add a  row to each of the characters of
row to each of the characters of  using minus one
using minus one  s and one such that the resulting string
s and one such that the resulting string  belongs to
belongs to 
We must show that  is star-free. As has
is star-free. As has  quantifiers, then by assumption is star-free regular.
quantifiers, then by assumption is star-free regular.
Note that has one more row than because it has one more free variable. Without loss of generality we may suppose it is the bottom row.
The Tricky Point
Since we have an existential quantifier we might think we can simply delete the last row of . But here is a counterexample to show why we must be careful not to “lose information”:
Let 

and 

Notice that  equals with its final row removed. We have
equals with its final row removed. We have 

and 

Then 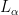 is the language of strings with at least three zeroes in a row and
is the language of strings with at least three zeroes in a row and  is the language of strings with at least two zeroes in a row.
is the language of strings with at least two zeroes in a row.
We cannot add a second row consisting of zeroes and one 1 to each word  in
in  to force to be in . For a trivial example, consider the word
to force to be in . For a trivial example, consider the word 

The fault can be interpreted as not being recoverable uniquely from owing to a loss of information. We could also pin the fault in this case on the central 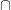 , noting that
, noting that  is generally not equivalent to
is generally not equivalent to  .
.
Either way, this means we must be careful with how we express (the final row of) . The idea is to give in segments such that the final row of each segment is all-zero or a single , so that the act of removing the final row could be inverted. This is the crux of the proof. To handle it we employ the unique DFA for the regular expression already obtained by induction for .
Main Part of the Proof
By the Myhill-Nerode Theorem, there must exist a unique minimal automaton  over the alphabet of our stacked words defining the language of .
over the alphabet of our stacked words defining the language of .
The state set  of can be partitioned into the set
of can be partitioned into the set 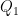 of states before any is read in the final row, the set
of states before any is read in the final row, the set 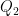 of states reached after reading a in the final row, plus a dead state
of states reached after reading a in the final row, plus a dead state  belonging to neither nor . The start state belongs to and all accepting states belong to . Since any stacked word and therefore accepting computation has exactly one in any row, all arcs within and must have a only s in their final row, while the letters connecting states in and must have a in their final row. The minimality of enforces these properties. Here is a sketch, omitting :
belonging to neither nor . The start state belongs to and all accepting states belong to . Since any stacked word and therefore accepting computation has exactly one in any row, all arcs within and must have a only s in their final row, while the letters connecting states in and must have a in their final row. The minimality of enforces these properties. Here is a sketch, omitting :

Let  be the set of edges that cross from to . With
be the set of edges that cross from to . With  we can label their origins by states
we can label their origins by states  (not necessarily all distinct), and similarly label their characters by
(not necessarily all distinct), and similarly label their characters by  and the destination states by
and the destination states by  . Then
. Then  collects all the characters used by that have a in row (except those into or at the dead state ). We can identify with the set of instructions
collects all the characters used by that have a in row (except those into or at the dead state ). We can identify with the set of instructions  .
.
Finally let  denote the set of strings that take from state
denote the set of strings that take from state  to state
to state  , and let
, and let  . Then we can define by the expression
. Then we can define by the expression

What remains is to find expressions for  and
and  for each
for each  . The latter is easy: Pick any string
. The latter is easy: Pick any string 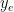 in . Then
in . Then

The closure of under left quotients supplies expressions  for .
for .
The case of , however, is harder. What we would like to do is choose some (any) string  that goes from
that goes from  to an accepting state and claim that
to an accepting state and claim that  . The problem is that might be accepted from some state
. The problem is that might be accepted from some state  that has an incoming arc on the same character
that has an incoming arc on the same character  from some other state
from some other state  . Then
. Then  , which is disjoint from , is included also in
, which is disjoint from , is included also in  . There may, however, be strings
. There may, however, be strings  and
and  such that
such that  is not accepted by . Then the string would be wrongly included if we substituted
is not accepted by . Then the string would be wrongly included if we substituted  for (or for
for (or for  ) in (1).
) in (1).
There is also a second issue when crossing edges on the same character 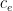 come in from distinct states
come in from distinct states  to the same state . To fix all this, we need to use sets of strings that distinguish
to the same state . To fix all this, we need to use sets of strings that distinguish 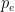 from all the other states . This requires the most particular use of the minimality of : If
from all the other states . This requires the most particular use of the minimality of : If  , then there is either (or both):
, then there is either (or both):
-
a string
 in
in  , or
, or
-
a string
 in
in  .
.
The strings in question need not begin with a character in —they need not cross right away. Let  stand for a choice of strings of the former kind,
stand for a choice of strings of the former kind,  the latter kind, covering all states . Then
the latter kind, covering all states . Then

We could not use just the complement  of
of  because that would allow strings that violate the “one ” condition in the rows. Note that
because that would allow strings that violate the “one ” condition in the rows. Note that  . Whether one can do the induction for and
. Whether one can do the induction for and  in tandem without invoking is a riddle we pose at the end.
in tandem without invoking is a riddle we pose at the end.
Either way, the closure of under right quotients yields a star-free expression  for . Then we just have to plug our expressions and into (1) to get a star-free expression
for . Then we just have to plug our expressions and into (1) to get a star-free expression  for . Now we are ready for the crude final step:
for . Now we are ready for the crude final step:
Form  by knocking out the last entry in every character occurring in
by knocking out the last entry in every character occurring in  . Then represents
. Then represents  .
.
To prove this final statement, first suppose 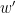 is a stacked word in . Then satisfies
is a stacked word in . Then satisfies  , so there is a value so that satisfies with set equal to the value . This means that the stacked word formed from and a last row with in position belongs to and hence matches . Since is obtained by knocking out the last row of , matches
, so there is a value so that satisfies with set equal to the value . This means that the stacked word formed from and a last row with in position belongs to and hence matches . Since is obtained by knocking out the last row of , matches 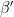 .
.
The converse is the part where the tricky point we noted at the outset could trip us up. Suppose matches . From the form of (1) as a union of terms  , we can trace how is matched to identify a place in that matches a “middle character”
, we can trace how is matched to identify a place in that matches a “middle character”  obtained from a in a crossing edge. Putting a in a new row underneath this place and s elsewhere hence makes a word that matches the unique regular expression
obtained from a in a crossing edge. Putting a in a new row underneath this place and s elsewhere hence makes a word that matches the unique regular expression  obtained by appending a component to every “middle character” and a to all other characters in . Then is equivalent to
obtained by appending a component to every “middle character” and a to all other characters in . Then is equivalent to  , so satisfies . Since the last row that was added to amounts to supplying a value for the variable
, so satisfies . Since the last row that was added to amounts to supplying a value for the variable 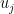 , it follows that satisfies with
, it follows that satisfies with  , hence satisfies . This yields
, hence satisfies . This yields  and so the entire induction goes through.
and so the entire induction goes through. 
Open Problems
First, as an end note, the end of the proof wound up different from what we envisioned until polishing this post. It originally applied the distinct-states argument to states  on the far side of the crossing, but we had to backtrack on having previously thought that the “second issue” did not matter. Two other questions we pose for our readers:
on the far side of the crossing, but we had to backtrack on having previously thought that the “second issue” did not matter. Two other questions we pose for our readers:
-
Do the definitions of and need to extend over all states
 , not just the other states on the border?
, not just the other states on the border?
-
Is needed in (2), or in the proof overall?
A larger question concerns how the size of the translated expressions increases as we add more quantifiers. We discuss the blowup in terms of quantifier depth and length  . Let
. Let 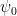 be a first-order formula with no quantifiers and let
be a first-order formula with no quantifiers and let  denote with quantifiers applied to it. Also let
denote with quantifiers applied to it. Also let  be a star-free translation of and the length of , denoted by len
be a star-free translation of and the length of , denoted by len , equal .
, equal .
To obtain  from we represent by a union over crossing edges between and and the final states of of the concatenation of prefix and suffix languages and a crossing character between them. We have that gives a decent approximation for—worst-case—length of the prefix languages, suffix languages and the product of crossing edges and final states. Using these approximations we have
from we represent by a union over crossing edges between and and the final states of of the concatenation of prefix and suffix languages and a crossing character between them. We have that gives a decent approximation for—worst-case—length of the prefix languages, suffix languages and the product of crossing edges and final states. Using these approximations we have  . Iterating gives
. Iterating gives  ,
,  , and in general,
, and in general,  . This says that our blowup could be doubly exponential. Is there a tighter estimate?
. This says that our blowup could be doubly exponential. Is there a tighter estimate?
Our final question is: how well do our “stacked words” help to visualize the proof? Are they helpful for framing proofs of equivalences between language classes and logics that are higher up?
Like this:
Like Loading...
Related



Shouldn’t a proof of Theorem 1 provide an Algorithm that, given an FO[<]-formula, outputs a corresponding r.e. expression?
Thanks for noting that desire. Our proof does indeed yield a recursive procedure to compute the SF expression. It needs to include the computation of expressions for left and right quotients from the lemmas in the Part 1 post. Then you carry out each step of the induction beginning with the quantifier-free matrix of the formula, and computing the minimal DFAs at each step of re-introducing a quantifier. Under “Open Problems” we note that the size blowup from this algorithm is, however, severe. We would love to know if there is a (proof that yields a) more-efficient algorithm.