Taming Some Inequalities
As used to solve a classic problem about distinguishing distributions

|
|
Composite of src1, src2 |
Gregory Valiant and Paul Valiant are top researchers who are not unrelated to each other. Families like the Valiants and Blums could be a subject for another post—or how to distinguish from those who are unrelated.
Today Ken and I wish to talk about a wonderful paper of theirs, “An Automatic Inequality Prover and Instance Optimal Identity Testing.”
I really like this paper, which I saw at FOCS 2014. I am less keen on the title—it suggests to me that they are working on some type of AI area. The phrase “Automatic Inequality Prover” sounds like an algorithm that takes in an inequality and outputs a proof that it is correct. Of course it does this only when the inequality is true. This is not what they do.
Ken chimes in: The paper has a neat mix of other ideas. There are natural cases of extremely succinct descriptions of strings that would take double exponential time to write out. It is notable that the formal system underlying their derivation of inequalities does not yield exponential complexity (let along undecidability) but stays within linear programming—do 
The Result on Distributions
They study the problem of telling one distribution from another. Suppose that 


The question is how many independent samples are needed to distinguish the two cases: (i) 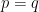
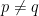
The answer is too many, since 

Now they are able to give essentially optimal answers to the question. There is a twist on the notion of optimal. Given the distribution 





Theorem 1 There is a global constant
,
, such that for all distributions
all sufficiently small
(possibly depending on
), and every tester
given white-box knowledge of
of size
from the unknown distribution
there exists a distribution
that is either
, such that the probability over
giving the wrong answer is at least
.
We can “almost” jump 


See their paper for the details on 

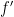

This improved a previous upper bound that had 
Hairy and Basic Inequalities
What strikes us even more is the “Automatic 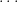
This leads to the neatest part of their paper, in our opinion. They give a complete characterization of a general class of inequalities that extend Cauchy-Schwarz, Hölder’s inequality, and the monotonicity of 



For example, their expression 



so it relates to long-known bounds involving 




If we raise both sides to the power 


so with 


Thus the original form (1) for 



When we have a second non-negative sequence 


We can obtain dual forms here too, and it helps to consider substitutions of the form 
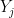
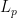



What They Prove
Let’s just state their main auxiliary result. Specifically, they determine for all length-




holds for all 

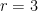




Theorem 2 The inequality (3) holds if and only if the left-hand side can be expressed as a finite product of positive powers of instances of the left-hand sides of the basic
and Hölder inequalities.
Moreover, there is an algorithm that in time polynomial in
and the maximum bits in any
,
, or
will output the terms of such a product if the inequality is true, or a description of a counterexample
if it is false.
The proof uses variables standing for the logarithms of sums of the form 



The process is so nicely effective that they are able to represent it by a human-friendly game on grid-points in the plane that is somewhat reminiscent of (and easier than) the solitaire peg-jumping game—well worth a look. They say:
Our characterization is of a non-traditional nature in that it uses linear programming to compute a derivation that may otherwise have to be sought through trial and error, by hand. We do not believe such a characterization has appeared in the literature, and hope its computational nature will be useful to others, and facilitate analyses like the one here.
In particular, it helped them with inequalities involving that “hairy” number
Why Isn’t it Exponential?
The short answer to why their algorithm runs in polynomial time is that it involves linear programming. There isn’t a tight analogy between their game moves and basic pivot moves of the simplex algorithm, however, because there are cases where the latter takes exponential time. It is unclear to us whether they are using a subcase of linear programming that stops short of being P-complete, or whether this will lead to new P-complete problems involving inequalities. They do have an even more general form with (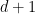



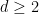


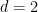
Most notable is that the minimum dimension 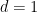

The middle factor is legal since 





There are 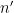



We close with a speculation about duality and dimension. The 


Open Problems
Can you find further applications for their result on inequalities? Can the class of inequalities that can be given an “automatic” treatment be extended further? For one instance we mention the Chebychev sum inequality

which depends critically on the monotone orderings 



typo, should be: c=(1/2,1/2,-1)
nicely written!